Conjugate Posteriors
Overview
Teaching: min
Exercises: minQuestions
Objectives
Stationary Distributions and Markov Chains
Stationary Markov chains
A random process \(Y = Y_1, Y_2, \ldots\) is said to be stationary if the marginal probability of a sequence of elements does not depend on where it starts in the chain. In symbols, a discrete-time random process \(Y\) is stationary if for any \(t \geq 1\) and any sequence \(u_1, \ldots, u_N \in \mathbb{R}^N\) of size \(N\), we have
\[p_{Y_1, \ldots, Y_N}(u_1, \ldots, u_N) = p_{Y_t, \ldots, Y_{t + N}}(u_1, \ldots, u_N)\]None of the chains we will construct for practical applications will be stationary in this sense, because we would need to know the appropriate initial distribution \(p_{Y_1}(y_1)\). For example, consider the fishes example in which we know the transition probabilities, but not the stationary distribution. If we run long enough, the proportion of pike stabilizes
Stationary distributions
Although we will not, in practice, have Markov chains that are stationary from \(t = 1\), we will use Markov chains that have stationary distributions in the limit as \(t \rightarrow \infty\). For a Markov chain to be stationary, there must be some \(q\) such that
\[p_{Y_t}(u) = q(u)\]for all \(t\), starting from \(t = 0\). Instead, we will have an equilibrium distribution \(q\) that the chain approaches in the limit as \(t\) grows. In symbols,
\[\lim_{t \rightarrow \infty} \ p_{Y_t}(u) = q(u).\]Very confusingly, this equilibrium distribution \(q\) is also called a stationary distribution in the Markov chain literature, so we will stick to that nomenclature. We never truly arrive at \(q(u)\) for a finite \(t\) because of the bias introduced by the initial distribution \(p_{Y_1}(u) \neq q(u)\). Nevertheless, as with our earlier simulation-based estimates, we can get arbitrarily close after suitably many iterations.^[The last section of this chapter illustrates rates of convergence to the stationary distribution, but the general discussion is in the later chapter on continuous-state Markov chains.]
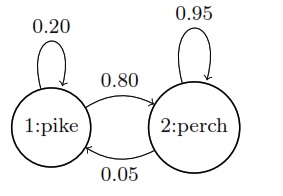
Reconsider the example of a process \(Y = Y_1, Y_2, \ldots\) of fishes, where 1 represents a pike and 0 a perch. We assumed the Markov process \(Y\) was governed by
\[\begin{array}{rcl} \mbox{Pr}[Y_{t + 1} = 1 \mid Y_t = 1] & = & 0.20 \\[4pt] \mbox{Pr}[Y_{t + 1} = 1 \mid Y_t = 0] & = & 0.05 \end{array}\]Rewriting as a probability mass function,
\[p_{Y_{t + 1} \mid Y_t}(j \mid i) = \theta_{i, j},\]where \(\theta_{i, j}\) is the probabiltiy of a transition to state \(j\) given that the process is in state \(i\). For the pike and perch example, \(\theta\) is fully defined by
\[\begin{array}{rcl} \theta_{1, 1} & = & 0.20 \\ \theta_{1, 2} & = & 0.80 \\ \hline \theta_{2, 1} & = & 0.05 \\ \theta_{2, 2} & = & 0.95. \end{array}\]These numbers are normally displayed in the form of a transition matrix, which records the transitions out of each state as a row, with the column indicating the target state,
\[\theta = \begin{bmatrix} 0.20 & 0.80 \\ 0.05 & 0.95 \end{bmatrix}.\]The first row of this transition matrix is \((0.20, 0.80)\) and the second row is \((0.05, 0.95)\). Rows of transition matrices will always have non-negative entries and sum to one, because they are the parameters to categorical distributions.^[Vectors with non-negative values that sum to one are known as unit simplexes and matrices in which every row is a unit simplex is said to be a stochastic matrix. Transition matrices for finite-state Markov chains are always stochastic matrices.]
Now let’s take a really long run of the chain with \(T = 1\,000\,000\) fish to get a precise estimate of the long-run proportion of pike.
import numpy as np
np.random.seed(1234)
T = int(1e6)
y = np.empty(T, dtype=int)
for k in range(2):
y[0] = k
for t in range(1, T):
y[t] = np.random.binomial(1, 0.2 if y[t - 1] == 1 else 0.05)
print(f"initial state = {k}; simulated proportion of pike = {y.mean():.3f}")
initial state = 0; simulated proportion of pike = 0.059
initial state = 1; simulated proportion of pike = 0.059
The initial state doesn’t seem to matter. That’s because the rate of 5.9% pike is the stationary distribution. More formally, let \(\pi = (0.059, 1 - 0.059)\) and note that^[In matrix notation, if \(\pi\) is considered a row vector, then \(\pi = \theta \, \pi.\)]
\[\pi_i = \sum_{j = 1}^2 \pi_j \times \theta_{j, i}.\]If \(\pi\) satisfies this formula, then it is said to be the stationary distribution for \(\theta.\)
If a Markov chain has a stationary distribution \(\pi\) and the initial distribution of \(Y_1\) is also \(\pi\), then it is stationary.
Reducible chains
The Markov chains we will use for sampling from target distributions will be well behaved by construction. There are, however, things that can go wrong with Markov chains that prevent them from having stationary distributions. The first of these is reducibility. A chain is reducible if it can get stuck in a state from which other states are not guaranteed to be revisited with probability one.
State diagram for a reducible finite Markov chain. The chain will eventually get stuck in state 3 and never exit to visit states 1 or 2 again.
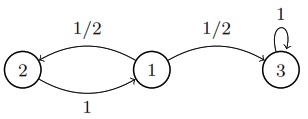
If we start the chain in state 1, it will eventually transition to state 3 and get stuck there.^[State 3 is what is known as a sink state.] It’s not necessary to get stuck in a single state. The same problem arises if state 3 has transitions out, as long as they can’t eventually get back to state 1.
State diagram for another reducible finite Markov chain. The chain will eventually get stuck in state 3 and 4 and never exit to visit states 1 or 2 again.
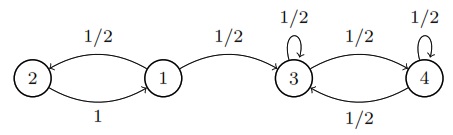
In this example, the chain will eventually fall into a state where it can only visit states 3 and 4.
Periodic chains
A Markov chain can be constructed to cycle through states in a regular (probabilistic) pattern. For example, consider the following Markov chain transitions.
State diagram for finite Markov chain generating periodic state sequences \(\\ldots, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, \\ldots\).
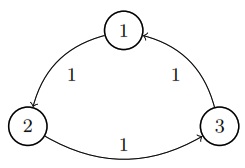
Regular cycles like this defeat the existence of a stationary distribution. If \(Y_1 = 2\), the entire chain is deterministically defined to be
\[Y = 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, \ldots.\]Clearly \(p_{Y_t} \neq p_{Y_{t+1}}\), as each concentrates all of its probability mass on a different value.
On the other hand, this chain is what is known as wide-state stationary in that using long-running frequency estimates are stable. The expected value is \(\frac{1 + 2 + 3}{3} = 2\) and the standard deviation is \(\sqrt{\frac{1^2 + 0^2 + 1^2}{3}} \approx 0.47\). More formally, the wide-state expectation is calculated as
\[\lim_{T \rightarrow \infty} \ \frac{1}{T} \sum_{t=1}^T Y_t \rightarrow 2.\]The definition of periodicity is more subtle than just deterministic chains. For example, the following transition graph is also periodic.
State diagram for finite Markov chain generating periodic state sequences alternating between state 1 and either state 2 or state 3.
Rather than a deterministic cycle, it cycles between the state 1 and the pair of states 2 and 3. A simulation might look like
\[y^{(1)} = 1, 2, 1, 2, 1, 2, 1, 3, 1, 3, 1, 2, 1, 3, 1, 2, \ldots\]Every other value is a 1, no matter whether the chain starts in state 1, 2, or 3. Such behavior means there’s no stationary distribution. But there is a wide-sense stable probability estimate for the states, namely 50% of the time spent in state 1, and 25% of the time spent in each of states 2 and 3.
Convergence of finite-state chains
In applied statistics, we proceed by simulation, running chains long enough that they provide stable long-term frequency estimates. These stable long-term frequency estimates are of the stationary distribution \(\mbox{categorical}(\pi)\). All of the Markov chains we construct to sample from target distributions of interest (e.g., Bayesian posterior predictive distributions) will be well-behaved in that these long-term frequency estimates will be stable, in theory.^[In practice, we will have to be very careful with diagnostics to avoid poor behavior due to floating-point arithmetic combined with approximate numerical algorithms.]
In practice, none of the Markov chains we employ in calculations will be stationary for the simple technical reason that we don’t know the stationary distribution ahead of time and thus cannot draw \(Y_1\) from it.^[In the finite case, we actually can calculate it either through simulation or as the eigenvector of the transition matrix with eigenvalue one (which is guaranteed to exist). An eigenvector of a matrix is a row vector \(\pi\) such that \(c \times \pi = \theta \, \pi,\) where \(c\) is the eigenvalue. This is why Google’s PageRank algorithm is known to computational statisticians as the “billion dollar eigenvector.” One way to calculate the relevant eigenvector of a stochastic matrix is by raising it to a power, starting from any non-degenerate initial simplex vector \(\lambda\), \(\lim_{n \rightarrow \infty} \lambda \, \theta^n = \pi.\) Each \(\theta^n = \underbrace{\theta \times \theta \times \cdots \times \theta}_{\textstyle n \ \mbox{times}}\) is a transition matrix corresponding to taking \(n\) steps in the original transition matrix \(\theta\).] What we need to know is conditions under which a Markov chain will “forget” its initial state after many steps and converge to the stationary distribution.
All of the Markov chains we will employ for applied statistics applications will be well behaved in the sense that when run long enough, the distribution of each element in the chain will approach the stationary distribution. Roughly, when \(t\) is large enough, the marginal distribution \(p_{Y_t}\) stabilizes to the stationary distribution. The well-behavedness conditions required for this to hold may be stated as follows
Fundamental Convergence Theorem. If a Markov chain \(Y = Y_1, Y_2, \ldots\) is (a) irreducible, (b) aperiodic, and (c) has a stationary distribution \(\mbox{categorical}(\pi)\), then
\[\lim_{t \rightarrow \infty} \ P_{Y_t}(u) \rightarrow \mbox{categorical}(u \mid \pi).\]What this means in practice is that we can use a single simulation,
\[y^{(1)} \ = \ y^{(1)}_1, y^{(1)}_2, \ldots, y^{(1)}_T\]to estimate the parameters for the stationary distribution. More specifically, if we define \(\pi\) by
\[\widehat{\pi}_i = \frac{1}{T} \sum_{t = 1}^T \mathrm{I}[y_t^{(1)} = i]\]then we can estimate the stationary distribution as \(\mbox{categorical}(\widehat{\pi}).\)
As a coherence check, we often run a total of \(M\) simulations of the first \(T\) values of the Markov chain \(Y\).
\[\begin{array}{rcl} y^{(1)} & = & y_1^{(1)}, y_2^{(1)}, \ldots, y_T^{(1)} \\[4pt] y^{(2)} & = & y_1^{(2)}, y_2^{(2)}, \ldots, y_T^{(2)} \\[2pt] \vdots \\[2pt] y^{(M)} & = & y_1^{(M)}, y_2^{(M)}, \ldots, y_T^{(M)} \end{array}\]We should get the same estimate from using \(y^{(m)}\) from a single simulation \(m\) as we get from using all of the simulated chains \(y^{(1)}, \ldots, y^{(M)}\).^[We’d expect lower error from using all of the chains as we have a larger sample with which to estimate.]
How fast is convergence?
The fundamental theorem tells us that if a Markov chain \(Y = Y_1, Y_2, \ldots\) is ergodic (aperiodic and irreducible) and has a stationary distribution, then the distribution of \(Y_t\) converges to the stationary distribution in the limit. But it doesn’t tell us how fast.
As with everything else, we’ll go at this by simulation to establish intuitions. In particular, we’ll consider three chains that have \(\mbox{bernoulli}(0.5)\) as their stationary distribution (a fair coin toss).
First, we will consider a Markov chain producing independent Bernoulli draws.
State diagram for finite Markov chain generating independent draws.
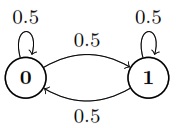
Whether it is currently in state 0 or state 1, there is a 50% chance the next state is 0 and a 50% chance it is 1. Thus each element of the process is generated independently and is identically distributed,
\[Y_t \sim \mbox{bernoulli}(0.5).\]Therefore, the stationary distribution must also be \(\pi = (0.5, 0.5)\), because
\[\begin{array}{rcl} \pi_1 & = & \pi_1 \times \theta_{1, 1} + \pi_2 \times \theta_{2, 1} \\[4pt] 0.5 & = & 0.5 \times 0.5 + 0.5 \times 0.5 \end{array}\]and
\[\begin{array}{rcl} \pi_2 & = & \pi_1 \times \theta_{1, 2} + \pi_2 \times \theta_{2, 2} \\[4pt] 0.5 & = & 0.5 \times 0.5 + 0.5 \times 0.5. \end{array}\]We can simulate 100 values and print the first 99 to see what the chain looks like.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def print_3_rows_of_33(y):
n = 0
for i in range(3):
row = [str(j) for j in y[n:n+33]]
print(" ".join(row))
n += 33
def sample_chain(M, init_state, theta):
y = [init_state]
for m in range(1, M):
y.append(np.random.choice([0, 1], size=1, p=theta[y[m-1], :])[0])
return y
def traceplot_bool(y):
df = pd.DataFrame({'iteration': range(1, len(y)+1), 'draw': y})
plot = sns.lineplot(data=df, x='iteration', y='draw')
plot.set(xlabel='iteration', ylabel='y', xticks=[1, 50, 100])
return plot
import numpy as np
np.random.seed(1234)
M = 100
theta = np.array([[0.5, 0.5], [0.5, 0.5]])
y = sample_chain(M, 1, theta)
print_3_rows_of_33(y)
1 0 1 0 1 1 0 0 1 1 1 0 1 1 1 0 1 1 0 1 1 0 1 0 0 1 1 0 1 0 1 1 0
1 0 1 1 0 1 0 1 0 0 0 1 1 1 0 1 0 1 0 1 1 0 1 1 1 1 1 1 0 1 0 0 0
0 0 1 0 0 1 1 0 0 0 1 0 1 0 0 0 1 1 1 1 0 1 1 1 0 0 1 1 1 0 1 1 1
An initial segment of a Markov chain \(Y = Y_1, Y_2, \ldots, Y_T\) can be visualized as a traceplot, a line plot of the value at each iteration.
Traceplot of chain producing independent draws, simulated for 100 time steps. The horizontal axis is time (\(t\)) and the vertical axis the value of e iteration number and the value is the value (\(Y_t\)).
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
def traceplot_bool(y):
df = pd.DataFrame({'iteration': range(1, len(y)+1), 'draw': y})
plot = sns.lineplot(data=df, x='iteration', y='draw')
plot.set(xlabel='iteration', ylabel='y', xticks=[0, 50, 100])
return plot
traceplot_bool(y)
plt.show()
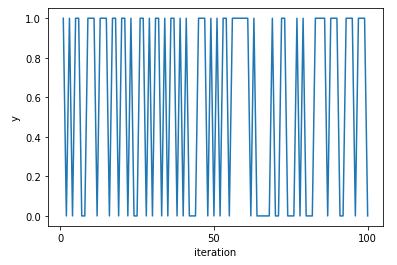
The flat segments are runs of the same value. This Markov chain occasionally has runs of the same value, but otherwise mixes quite well between the values.
So how fast do estimates of the stationary distribution based on an initial segment \(Y_1, \ldots, Y_T\) converge to \(\frac{1}{2}\)? Because each \(Y_t\) is independent and identically distributed, the central limit theorem tells us that the rate of convergence, as measured by standard deviation of the distribution of estimates, goes down as \(\frac{1}{\sqrt{T}}\) with an initial segment \(Y_1, \ldots, Y_T\) of the chain goes down in error as \(\sqrt{T}\)
Now consider a Markov chain which is still symmetric in the states, but with a tendency to stay in the same state.
State diagram for correlated draws.
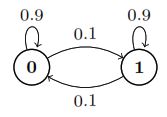
It has the same stationary distribution of 0.5. Letting \(\theta = \begin{bmatrix}0.9 & 0.1 \\ 0.1 & 0.9 \end{bmatrix}\) be the transition matrix and \(\pi = (0.5, 0.5)\) be the probabilities of the stationary distribution we see that the general formula is satisfied by this Markov chain,
\[\begin{array}{rcl} \pi_1 & = & \pi_1 \times \theta_{1, 1} + \pi_2 \times \theta_{2, 1} \\[4pt] 0.5 & = & 0.5 \times 0.9 + 0.5 \times 0.1 \end{array}\]The same relation holds for \(\pi_2\),
\[\begin{array}{rcl} \pi_2 & = & \pi_1 \times \theta_{1, 2} + \pi_2 \times \theta_{2, 2} \\[4pt] 0.5 & = & 0.5 \times 0.1 + 0.5 \times 0.9 \end{array}\]We can simulate from the chain and print the first 99 values, and then print the traceplot.
import numpy as np
np.random.seed(1234)
M = 100
theta = np.array([[0.9, 0.1], [0.1, 0.9]])
y = sample_chain(M, 1, theta)
print_3_rows_of_33(y)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Traceplot for chain with correlated draws.”
traceplot_bool(y)
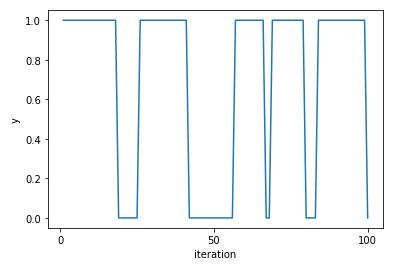
As expected, there are now long runs of the same value being produced. This leads to much poorer mixing and a longer time for estimates based on the draws to converge.
Finally, we consider the opposite case of a symmetric chain that favors moving to a new state each time step.
State diagram for anticorrelated draws.
Sampling, printing, and plotting the values produces

Chain with anticorrelated draws.
import numpy as np
np.random.seed(1234)
M = 100
theta = np.array([[0.1, 0.9], [0.9, 0.1]])
y = sample_chain(M, 1, theta)
print_3_rows_of_33(y)
1 0 1 0 1 0 1 0 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 0 1 1 0 1 0 1 0 1 0
1 0 1 0 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 0 1 1 0 1 1 0 1 0 1 0 1
0 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 1 0 1 0 1 0 1 0 1 0 1 1 0 1 0 1
Traceplot of chain with anticorrelated draws.
traceplot_bool(y)
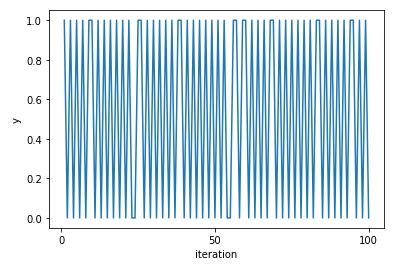
The draws form a dramatic sawtooth pattern as they alternate between zero and one.
Now let’s see how quickly estimates based on long-run averages from the chain converge in a side-by-side comparison. A single chain is enough to illustrate the dramatic differences.
import numpy as np
import pandas as pd
np.random.seed(1234)
def sample_chain(M, start, trans_matrix):
chain = np.zeros(M, dtype=int)
chain[0] = start
for i in range(1, M):
chain[i] = np.random.choice([0, 1], p=trans_matrix[chain[i-1], :])
return chain
def build_discrete_mcmc_df(trans_matrix, label, J, M):
df = pd.DataFrame({'y': [], 'x': [], 'chain': [], 'id': []})
for j in range(1, J+1):
y = np.cumsum(sample_chain(M, 1, trans_matrix)) / np.arange(1, M+1)
df = pd.concat([df, pd.DataFrame({'y': y, 'x': np.arange(1, M+1), 'chain': np.repeat(label, M), 'id': np.repeat(j, M)})])
return df
corr_trans = np.array([[0.9, 0.1], [0.1, 0.9]])
ind_trans = np.array([[0.5, 0.5], [0.5, 0.5]])
anti_trans = np.array([[0.1, 0.9], [0.9, 0.1]])
J = 25
M = int(1e4)
df_compare_discrete_mcmc = pd.concat([build_discrete_mcmc_df(corr_trans, 'correlated', J, M),
build_discrete_mcmc_df(ind_trans, 'independent', J, M),
build_discrete_mcmc_df(anti_trans, 'anticorrelated', J, M)])
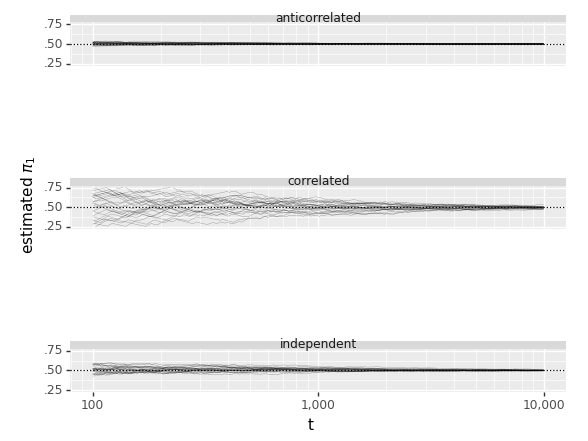
Estimate of the stationary probability \(\pi_1\) of state 1 as a function of \(t\) under three conditions, correlated, independent, and anticorrelated transitions. For each condition, 25 simulations of a chain of size \(T = 10,000\) are generated and overplotted.
import numpy as np
import pandas as pd
from plotnine import *
np.random.seed(1234)
def sample_chain(M, start_state, trans_matrix):
chain = np.zeros(M)
chain[0] = start_state
for i in range(1, M):
chain[i] = np.random.choice([0, 1], p=trans_matrix[int(chain[i-1]), :])
return chain
def build_discrete_mcmc_df(trans_matrix, label, J, M):
df = pd.DataFrame(columns=['y', 'x', 'chain', 'id'])
for j in range(J):
y = np.cumsum(sample_chain(M, np.random.choice([0, 1]), trans_matrix)) / (1 + np.arange(M))
df = pd.concat([df, pd.DataFrame({'y': y, 'x': 1+np.arange(M), 'chain': [label]*M, 'id': [j]*M})])
return df
corr_trans = np.array([[0.9, 0.1], [0.1, 0.9]])
ind_trans = np.array([[0.5, 0.5], [0.5, 0.5]])
anti_trans = np.array([[0.1, 0.9], [0.9, 0.1]])
J = 25
M = int(1e4)
df_compare_discrete_mcmc = pd.concat([
build_discrete_mcmc_df(corr_trans, 'correlated', J, M),
build_discrete_mcmc_df(ind_trans, 'independent', J, M),
build_discrete_mcmc_df(anti_trans, 'anticorrelated', J, M)
])
compare_discrete_mcmc_plot = (
ggplot(df_compare_discrete_mcmc, aes(x='x', y='y', group='id')) +
geom_hline(yintercept=0.5, linetype='dotted', size=0.5) +
facet_wrap('chain', ncol=1) +
geom_line(alpha=0.4, size=0.15) +
scale_x_log10(limits=[100, 10000], breaks=[1e2, 1e3, 1e4], labels=['100', '1,000', '10,000']) +
scale_y_continuous(limits=[0.25, 0.75], breaks=[0.25, 0.5, 0.75], labels=['.25', '.50', '.75']) +
xlab('t') +
ylab('estimated ' + r'$\pi_1$') +
theme_gray() +
theme(panel_spacing_y=1)
)
compare_discrete_mcmc_plot
Reversibility
These simple Markov chains wind up being reversible, in that the probability of being in a state \(i\) and then transitioning to state \(j\) is the same as that of being in state \(j\) and transitioning to state \(i\). In symbols, a discrete-valued Markov chain \(Y = Y_1, Y_2, \ldots\) is reversible with respect to \(\pi\) if
\[\pi_i \times \theta_{i, j} \ = \ \pi_j \times \theta_{j, i}.\]Reversibility is sufficient for establishing the existence of a stationary distribution.^[If a discrete Markov chain is reversible with respect to \(\pi\), then \(\pi\) is also the unique stationary distribution of the Markov chain.] Markov chains can have stationary distributions without being reversible.^[The reducible chains with we saw earlier are examples with stationary distributions that are not reversible.] But all of the Markov chains we consider for practical applications will turn out to be reversible.
1. Find the stationary distribution \(p_{0}^{0}, p_{1}^{0},\ldots\) for the Markov chain whose only nonzero transition probabilities are:
\(p_{j1} = \frac{j}{j+1},p_{j,j+1} = \frac{1}{j+1} (j = 1, 2,\ldots)\).
Solution
We can find the stationary distribution of the Markov chain by solving the system of equations:
\(\begin{aligned} p_0 &= p_0 \cdot \frac{1}{2} \\ p_j &= p_{j-1} \cdot \frac{j}{j+1} + p_j \cdot \frac{1}{j+1}, \quad j \geq 1 \end{aligned}\)
The first equation simply states that the probability of being in state 0 does not change, since there are no transitions out of state 0.
The second equation can be derived from the law of total probability:
the probability of being in state \(j\) can either come from being in state \(j-1\) and transitioning to state \(j\), or from already being in state \(j\) and staying there.
Solving for the first equation gives \(p_0 = 1\), since any constant multiple of the equation is also a solution.
For the second equation, we can simplify it by multiplying both sides by \((j+1)\) and rearranging:
\(p_{j-1} = \frac{j+1}{j} p_j, \quad j \geq 1\)
We can use this equation to express \(p_j\) in terms of \(p_{j-1}\) recursively:
\(\begin{aligned} p_1 &= p_0 \cdot \frac{1}{2} = \frac{1}{2} \\ p_2 &= \frac{2}{3} p_1 = \frac{1}{3} \\ p_3 &= \frac{3}{4} p_2 = \frac{1}{4} \\ & \cdots \\ p_j &= \frac{1}{j+1} p_{j-1} \end{aligned}\)
We can see that \(p_j = \frac{1}{j+1}\) for all \(j \geq 0\), which is the stationary distribution of the Markov chain.
2. Two gamblers \(A\) and \(B\) repeatedly play a game such that \(A's\) probability of winning is \(p\), while \(B's\) probability of winning is \(q = 1 - p\). Each bet is a dollar, and the total capital of both players is \(m\) dollars. Find the probability of each player being ruined, given that \(A's\) initial capital is \(j\) dollars.
Hint. Let \(e\), denote the state in which \(A\) has \(j\) dollars. Then the situation is described by a Markov chain whose only nonzero transition probabilities are: \(P_{00} = 1, P_{mm} = 1, P_{j,j+1}=p, P_{j,j+1}=q\) \((j = 1, \ldots , m -1)\).
Solution
Let e denote the state in which A has j dollars. We can describe the situation using a Markov chain with m+1 states, where state i represents the situation where A has i dollars. The transition probabilities are given by:
\(P_{i,i+1} = p\), for \(i = 0,1,...,j-1\)
\(P_{i,i+1} = q\), for \(i = j,j+1,...,m-1\)
\(P_{0,0} = P_{m,m} = 1\)
\(P_{i,j} = 0\) for all other \(i,j\)
Note that \(P_{0,0}\) and \(P_{m,m}\) are absorbing states, since once either player has lost all their money, the game ends.
To find the probability of each player being ruined, we can find the probability of reaching the absorbing states starting from state e. Let \(P_i\) denote the probability of reaching the absorbing state \(0\) starting from state \(i\), and \(Q_i\) denote the probability of reaching the absorbing state \(m\) starting from state \(i\).
We can set up a system of equations to solve for \(P_i\) and \(Q_i\):
\(P_{j} = p P_{j+1} + q P_{j-1}\)
\(Q_{j} = p Q_{j+1} + q Q_{j-1}\)
\(P_{0} = 1, P_{m} = 0\)
\(Q_{0} = 0, Q_{m} = 1\)
The first two equations represent the law of total probability: the probability of reaching the absorbing state from state \(j\) can either come from winning the next game and moving to state \(j+1\), or losing the next game and moving to state \(j-1\). The last two equations represent the boundary conditions: the probability of reaching the absorbing state is \(1\) if you are already in the absorbing state, and 0 otherwise.
We can solve for \(P_i\) and \(Q_i\) using standard techniques for solving linear systems of equations. The solution is:
\(P_i = (1 - (q/p)^j (p/q)^{m-j}) / (1 - (q/p)^m)\)
\(Q_i = (1 - (p/q)^{m-j} (q/p)^j) / (1 - (p/q)^m)\)
These formulas give the probability of each player being ruined, depending on their initial capital \(j\) and the total capital \(m\). Note that if \(p = q = 1/2\), then \(P_i = Q_i\) for all \(i\), since the game is fair and both players have the same chance of winning.
3. In the preceding problem, prove that if \(p > q\), then \(f's\) probability of ruin increases if the stakes are doubled.
Solution
Suppose that \(p > q\). Let \(P_j\) and \(Q_j\) denote the probabilities of ruin for A and B, respectively, when the stakes are $1.
Let \(P'_j\) and \(Q'_j\) denote the probabilities of ruin for \(A\) and \(B\), respectively, when the stakes are $2.
We can see that if A is ruined when the stakes are $1, then A will also be ruined when the stakes are $2.
This is because if A is ruined when the stakes are $1, then A has lost all of their money, which means that they would also lose all of their money if the stakes were doubled.
On the other hand, if A is not ruined when the stakes are $1, then A has some positive probability of winning and eventually reaching the total capital of $m.
When the stakes are doubled, A’s probability of winning each game is still p, but the amount of money that A wins in each game is now $2 instead of $1.
This means that A has a higher expected return on each bet, which increases their chances of reaching the total capital of $m.
Therefore, we can see that \(P'_j <= P_j\) for all \(j\), since if A is ruined when the stakes are $1, then A will also be ruined when the stakes are $2, and if A is not ruined when the stakes are $1, then A’s probability of ruin is lower when the stakes are $2.
Similarly, we can see that \(Q'_j >= Q_j\) for all j, since B’s probability of ruin is higher when the stakes are $2.
Therefore, we can conclude that if \(p > q\), then A’s probability of ruin increases if the stakes are doubled.
4. Prove that a gambler playing against an adversary with unlimited capital is certain to be ruined unless his probability of winning in each play of the game exceeds \(\frac{1}{2}\).
Solution
Suppose that a gambler playing against an adversary with unlimited capital has a probability of winning in each play of the game that is less than or equal to \(\frac{1}{2}\). We will prove that the gambler is certain to be ruined.
Let p be the gambler’s probability of winning in each play, and let \(q = 1 - p\) be the adversary’s probability of winning in each play.
Assume that the gambler starts with a capital of j dollars, and that each bet is for one dollar.
Let \(P_j\) denote the probability that the gambler is ruined starting with j dollars.
Suppose that the gambler has j dollars and plays until they are either ruined or have a total capital of m dollars.
Let \(X_k\) denote the gambler’s capital after the \(k^{th}\) bet, and let \(Y_k\) denote the adversary’s capital after the \(k^{th}\) bet. Then we have:
\(X_{k+1} = X_k + 1\) with probability \(p\)
\(X_{k+1} = X_k - 1\) with probability \(q\)
\(Y_{k+1} = Y_k - 1\) with probability \(p\)
\(Y_{k+1} = Y_k + 1\) with probability \(q\)
Note that \(X_k - Y_k\) is a martingale, since the expected value of \(X_{k+1} - Y_{k+1}\) given \(X_k - Y_k\) is equal to \(X_k - Y_k\).
This follows from the fact that the expected value of each of the four possible outcomes for \(X_{k+1} - Y_{k+1}\) given \(X_k - Y_k\) is \(X_k - Y_k\).
Let T denote the first time at which the gambler is ruined or has a total capital of m dollars.
Note that T is a stopping time with respect to the sequence of random variables \(X_0, X_1, ..., X_T\) and \(Y_0, Y_1, ..., Y_T\).
Therefore, we can apply the optional stopping theorem to obtain:
\(j - P_j = E[X_T - Y_T] = E[X_0 - Y_0] = 0\)
This implies that \(P_j = j\), which means that the gambler is certain to be ruined.
Therefore, we can conclude that a gambler playing against an adversary with unlimited capital is certain to be ruined unless their probability of winning in each play of the game exceeds \(\frac{1}{2}\).
Key Points